Experiment 1 - Importing Gatsby to Hashnode?
Attempt to convert HTML pages on Gatsby website to Markdown to import into Has
A fledgling engineer dabbling into areas of DevOps, AWS and automation. I enjoy tinkering with technology frameworks and tools to understand and gain visibility in the underlying mechanisms of the "magic" in them.
In the progress of accumulating nuggets of wisdom in the different software engineering disciplines!
The Why for this experiment
I was browsing through the 'Request for Article' (RFA) section for topics to explore. I saw the request on - "How to export from Gatsby To Hashnode" with some interest. Hashnode provides us with a platform to write our article in Markdown. This pique my curiosity on exploring if static websites can be converted to Markdown.
I considered the following points:
Hashnode provides different means to import our articles from other sources.
Format conversion is not a new topic. My initial thoughts were "Surely there must be a tool to do the conversion in the Gatsby plugin ecosystem"
The possibility of additional development efforts required through settings configuration
On a side note - while I didn't participate in Hashnode February Hackathon, I tried out Netlify. I must say, it has features that helped in this tinkering experiment to deploy the starter Gatsby static website quickly with just a few clicks 🙌🏼
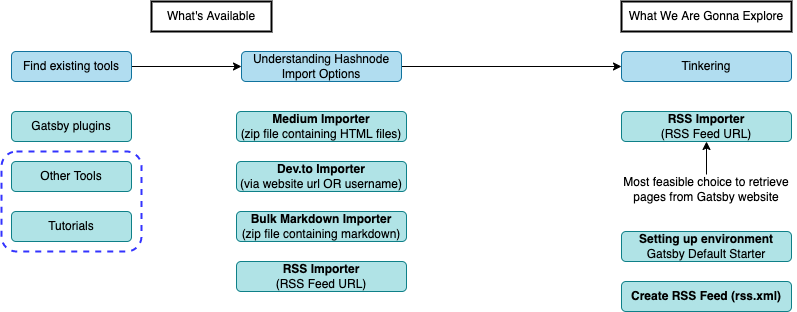
Overview of Tinkering Workflow
In this article, we will do the following
Find existing tools from Gatsby plugins, and understand the usage from tutorials
Understand Hashnode Import Options
Actual Tinkering!
Planning + Research + Quick Testing
Use of Gatsby plugins
So to kickstart the exploration, I started off by finding if there are existing Gatsby plugins from Gatsby official page. From a quick search, it seems one of the most downloaded plugin is gatsby-transformer-remark. I found an article from Digital Ocean by Joshua Tzucker that guide you on generating static pages from Markdown in Gatsby.
Food 4 Thought
While this is not what we are looking for, it would definitely provide new writers insights on their medium to write in (i.e. to write in Markdown!) to improve the portability of their content to publish across multiple platforms.
Use of Open Source Tools - Turndown
I also stumbled upon Shubhojyoti Bhattacharya's technical blog sharing his experience to do the conversion of HTML to Markdown for Gatsby from WordPress. This is probably the closest to what we are looking for, i.e. converting HTML to Markdown. This article, mentions an NPM package named Turndown.
Reading through the README of Turndown, I understand that this tool is useful for providing more granular control on the conversion by extending the existing rules. Though, I don't want to deep-dive for this experiment just yet.
Hashnode Import Options
Hashnode provides 4 options
Medium Importer
You can export your articles from Medium into a zip file.
Import the Medium zip file into Hashnode
Dev.to Importer
- Depending on the number of posts you want to port over to Hashnode, you can either provide a single post URL or your Dev.to username to import all posts
Bulk Markdown Importer
Self-explanatory, where it is a zip file with the Markdown articles.
If the Gatsby website is already written in Markdown, there won't be any issues.
RSS Importer
Requires you to provide an RSS Feed URL
Importer will either
Read from post body from the given RSS Tag
Scrape post from the post links provided in your RSS
Brute force approach
Replicating the supposed format of importers
Based on the description of each importer, I tried a naive approach of simply leveraging on the Medium importer. "Put the HTML files into a zip file, not a problem" - of course, that approach did not work 🤣 Same goes for the Dev.to Importer. Based on the error messages, I underestimated how stringent the required format will be.
Generating RSS Feed through online RSS generator
While the RSS generator tool can conveniently help to generate an RSS Feed, I realised the tags generated seems to take on the official Gatsby website pages instead of my website pages😵💫 This may be due to referencing to the links. This method is also most likely to be inefficient for scalability as the number of pages grows.
I must say the wrongly imported page looks visually appealing. So just thought of sharing anyway 🤣 Perhaps, if your Gatsby website includes images, this may be the look you may get when you import pages through your RSS feed.
But anyway, we have digressed🌚 So let's get back to the tinkering experiment
Setting the experiment's scope
Assumptions
Here are some assumptions before we start
The Gatsby website is already on a hosting platform (e.g. Netlify, Heroku etc). It is accessible to the general public via a domain.
There is a clear hierarchy of pages in the websites, where the page can be accessed via their unique individual website URL.
- There is a standardized structure in each article as well (e.g. headings, sections, paragraphs)
This may be a one-time migration that users are looking to change their approach of creating HTML pages to write their content in Markdown instead.
IMPORTANT: You have the required metadata to be used to generate RSS items.
<item>
<title>Example article</title>
<description>Short description of your article</description>
<link>URL to article</link>
<guid>Some unique ID</guid>
<pubDate>Timestamp of when the article is published</pubDate>
</item>
Limitations
I would like to bring up the following points up front as to the limitations of this experiment
The method derived from my tinkering is likely to consist of manual steps and likely amateur development effort due to my limited knowledge of Gatsby.
The static website project that I am using may be too simple for users with more established/complex websites to just use in a plug-and-play manner.
Test Setup
I am using my Gitlab repository consisting of the Gatsby default starter project (a static website) ready to deploy.
I am using Netlify to host the Gatsby static website to make it easily accessible on the internet.
It consists of some simple static pages (in Javascript/Typescript) to simulate the articles that I want to import into Hashnode.
As we will need to use some information from
siteMetadata, I have configured that in thegatsby-config.jsfile
// gatsby-config.js
module.exports = {
siteMetadata: {
title: `Gatsby Default Starter`,
description: `Kick off your next, great Gatsby project with this default starter. This barebones starter ships with the main Gatsby configuration files you might need.`,
author: `@gatsbyjs`,
siteUrl: `https://thirsty-northcutt-eb1b9a.netlify.app/`, //My Netlify Static Website Domain URL
},
plugin: [
..., // Excluded for brevity
]
}
Tinkering
What's Next
Generating RSS Feed seem to be the most feasible option to work towards. Hence, I decided to explore the Gatsby plugin gatsby-plugin-feed to generate an RSS feed via the project natively rather than relying on online RSS generators.
While Turndown would be the next step for granular controls for the HTML that may be specific to my sample website, I am looking to find a method that requires **minimal amount of development effort ** required and allows us to leverage what the existing Gatsby plugin ecosystem can offer.
Knowledge Prerequisites
To configure the gatsby-plugin-feed in gatsby-config.js, you will need to have basic knowledge of how to use/configure
GraphQL
Gatsby node configuration file (
gatsby-node.js) and Gatsby Node APIGatsby configuration file (
gatsby-config.js)NodeJS/Javascript
Setting up RSS Feed into Gatsby Default Starter Project
After a quick search into Gatsby's plugin ecosystem, I found the gatsby-plugin-feed. Being a beginner to the plugin, I went ahead to copy and paste the codes from the plugin page, following to a T. Clearly as a techie, I should have known things aren't that similar.
But then, if it has been so simple, I wouldn't have the chance to write this article🤣 In the subsequent sections, I will cover the development efforts and configuration required to generate the RSS feed.
I have created a separate article for troubleshooting. Please refer to this article here.
Defining the plugin configurations
Took me a while to figure out that the examples provided for gatsby-plugin-feed plugin are targeted at writers who have written their articles in Markdown before using plugins to transform them into an HTML page. The allMarkdownRemark is a node generated by gatsby-transformer-remark, which can be accessed via a GraphQL query.
This translates to modifications required in gatsby-config.js for the serialization. Considering I am using a starter project and the RSS feed requires specific details which are not available in the current GraphQL nodes, I decided to create my custom nodes.
Sourcing data for nodes
Referring to the Gatsby documentation on sourcing data, I modified the sample codes to match the pages I want the RSS feed to contain. While the data can come from anywhere e.g. a GET request to a database or calling an API, I will be creating them manually for the pages I want to import into Hashnode.
// gatsby-node.js
exports.sourceNodes = ({ actions, createNodeId, createContentDigest }) => {
// Create the nodes with required information to populate the RSS
const metaDatas = [
{ path: "/using-ssr/", title: "Using SSR", description: "This page talks about using SSR in Gatsby" },
{ path: "/page-2/", title: "Page 2 of my site", description: "Page 2 of default starter website" },
{ path: "/using-typescript/", title: "Using Typescript", description: "Summary of using typescript with Gatsby"}
];
// Will create the nodes at the build stages
metaDatas.forEach(metaData => {
const data = JSON.stringify({
title: metaData.title,
path: metaData.path
});
const nodeMeta = {
id: createNodeId(`metaData-${metaData.title}`),
internal: {
contentDigest: createContentDigest(metaData),
description: metaData.description,
content: data,
type: 'CustomMetaData' // You will see a Node named CustomMetaData available in the GraphQL
},
};
const node = Object.assign({}, data, nodeMeta)
actions.createNode(node);
});
}
Configuring gatsby-plugin-feed plugin
As part of the build stage, the gatsby-plugin-feed plugin will serialize the nodes retrieved from the GraphQL query into the RSS feed file in the gatsby-config.js where the plugin definitions reside.
Constructing the GraphSQL query
Note that the query used in the feed is specific to my website. Hence, you will need to do some testing on your website by running gatsby develop or npx gatsby develop if you do not have the Gatsby CLI installed locally. The command will start the development server. You will be able to access GraphiQL (in-browser IDE) to explore your site's data and schema.
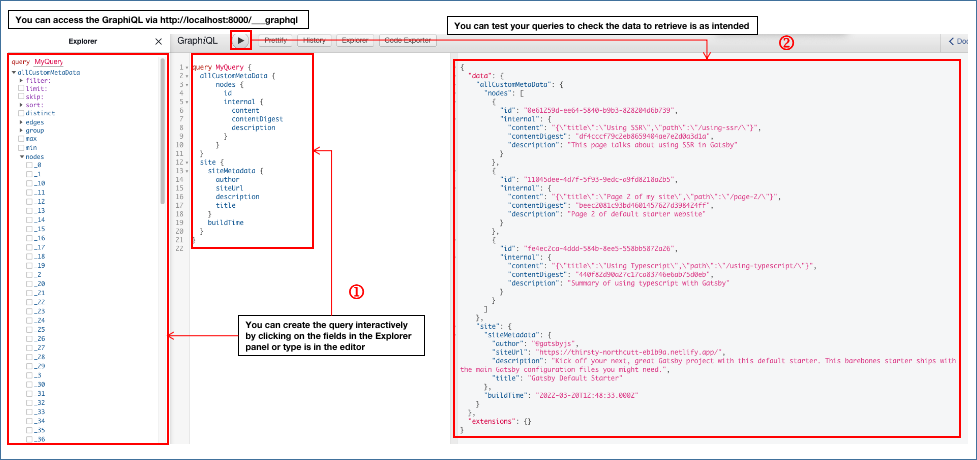
This is the GraphQL query I have created that will be able to provide the required data for the RSS feed
// Snippet for the GraphQL query in gatsby-plugin-feed definition
query: `
{
allCustomMetaData {
nodes {
id
internal {
content
contentDigest
description
}
}
}
site {
siteMetadata {
author
siteUrl
description
title
}
buildTime
}
}
`
Constructing the serialize function
After constructing the GraphQL query, you will need to define the serialize function on how you would like to format the data for the RSS feed.
// Snippet for serialize function for gatsby-plugin-feed definition
serialize: ({ query: { allCustomMetaData, site } }) => {
const crypto = require('crypto');
return allCustomMetaData.nodes.map(customNode => {
const content = JSON.parse(customNode.internal.content);
return Object.assign({}, customNode, {
date: site.buildTime,
title: content.title,
description: customNode.internal.description,
url: `${site.siteMetadata.siteUrl}${content.path}`,
guid: crypto.randomUUID(),
});
}) //END of allCustomMetaData
}, // END OF serialize
Combined view for plugin definition in gatsby-config.js
Here are the combined code snippets for the gatsby-plugin-feed plugin definition
// gatsby-node.js
module.exports = {
siteMetadata: {
... // Excluded for brevity
},
plugin: [
{
resolve: `gatsby-plugin-feed`,
options: {
query: `
{
site {
siteMetadata {
author
siteUrl
description
title
}
}
}
`,
feeds: [
{
title: "Sample RSS Feed",
output: "rss.xml",
query: `
{
allCustomMetaData {
nodes {
id
internal {
content
contentDigest
description
}
}
}
site {
siteMetadata {
author
siteUrl
description
title
}
buildTime
}
}
`,
serialize: ({ query: { allCustomMetaData, site } }) => {
const crypto = require('crypto');
return allCustomMetaData.nodes.map(customNode => {
const content = JSON.parse(customNode.internal.content);
return Object.assign({}, customNode, {
date: site.buildTime,
title: content.title,
description: customNode.internal.description,
url: `${site.siteMetadata.siteUrl}${content.path}`,
guid: crypto.randomUUID(),
});
}) //END of allCustomMetaData
}, // END OF serialize
}
]
}
}
..., // Other plugins excluded for brevity
]
}
Build and Deploy
To verify that the rss.xml is generated with the right items in the feed, run gatsby build or npx gatsby build to generate the public folder for the production build. Once ready, you can deploy it to your hosting platform.
Import into Hashnode
You will see that the description under "Post body tag name" mentioned the tags being
content:encodedandcontent. These are found in RSS 1.0.In our case, our RSS feed is RSS 2.0, which does not have any mandatory behaviour required to encode the content. Please check the
Scrape post instead of getting post body from the RSS Feedoption.
Image Annotations
Provide your website's RSS Feed URL. Remember to check "Scrape post instead of getting the post body from the RSS Feed, unless you have configured your RSS to be using the RSS tags.
You will see this loading prompt as Hashnode attempts to import your articles.
If successful, you should be able to see the title of your articles.
If Hashnode fails to get any pages, it will prompt you with warning icons.
If you opt to publish to the blog directly, the articles will be published as pages in Hashnode. You can edit it if you intend to put them under the series.
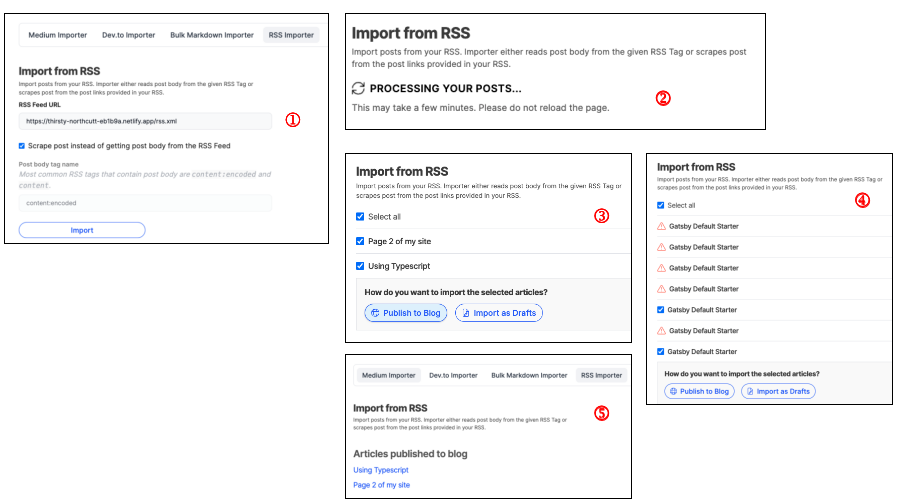
And that's it! The Gatsby static website pages have been imported into Hashnode! You can take a look at the Netlify website as well as the imported pages.
For the "Using Typescript" page,
Original: https://thirsty-northcutt-eb1b9a.netlify.app/using-typescript/
Imported page: https://bernicecpz.hashnode.dev/using-typescript
For "Page 2" page,
Original: https://thirsty-northcutt-eb1b9a.netlify.app/page-2/
Imported page: https://bernicecpz.hashnode.dev/page-2-of-my-site
Considerations/Caveats
As this experiment is tested on a barebone static website i.e. the Gatsby default starter project, it may not be fully scalable for content writers to try to shift the entirety of their articles all at once. Below are some considerations if you are looking to use the workflow for your website
- Page Format
- I believe the RSS importer method works best for websites with pages that share similar HTML tags/formats and/or with simple formats. This is so that the pages imported into Hashnode will still retain a similar structure in terms of image placements. But of course, one cannot expect the pages to be the same, further modifications may be required depending on how complex the HTML article was being formatted.
- Parsing of content in Markdown syntax
- There may have been some unintended/incorrect formatting of the content. Taking for example the backtick(`) in the article would result in some text being interpreted as a code section.
- The complexity of the web components within the HTML article
- As mentioned under the limitations of this experiment, if more niche requirements are needed, Turndown may be a better solution to have more granular control in the specific HTML tags to convert to Markdown.
Summary and Final Thoughts
So the general workflow is to create an RSS feed and make it publicly accessible to provide an RSS feed URL to import your articles into Hashnode.
I had spent more time doing this experiment than I would like to admit. But hey, it's a small win in this deceivingly simple conversion 😬 Upon finishing writing this article, I had a sudden realisation that there may be an area of contention as to whether I may be faking this as the results are seemingly the same as just manually creating the pages 🤣
Nonetheless, I have retained the imported pages and left the Netlify website running if you would like to refer to it. Here's the link to the Gitlab repository. Do try it out and let me know if you find this useful!
That's all for now, folks! Hope you enjoy this tinkering session, cheers🍻
Resources
Here are the resources mentioned in the article. Happy reading!
Documentations
Reading materials
For this articles, I mostly gained insights from tutorials from technical blogs and/or platforms. So kudos to the tech community!
Making an RSS Feed for a Gatsby Mdx Blog
- Thanks to the comment in this blog, I figured out the error and subsequently the method to manipulate the data in GraphQL!
How to Add an RSS Feed to Your Gatsby Site
This is a good guide for you if you are already using Markdown for your pages.
The starter project provided in this technical blog contains Markdown pages.
Online Tools/ Starter Projects from tutorials
![[DH] Keeping an organised inventory of annotated screenshots](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1731688657857%2Fcaeeeb6f-1530-4c88-a820-d22deaf0391e.png&w=3840&q=75)



